
قبل فترة، راج على مواقع التواصل الاجتماعي، منشور يتناول خطأً وقع فيه نموذج الذكاء الاصطناعي الخاص بشركة "ميتا" Meta AI، إذ طلب منه أحد المستخدمين ذكر سورة "الفلق" من القرآن، فأخطأ في نصّها، ما أشعل موجةً من الجدل وصلت إلى اتهام "ميتا AI"، بأنه "المسيح الدجّال" لهذا العصر، وسط دعوات إلى مقاطعته وعدم الإقبال على تعلّمه "عصمةً للدين"، وهروباً من "مخاطره على العقيدة".
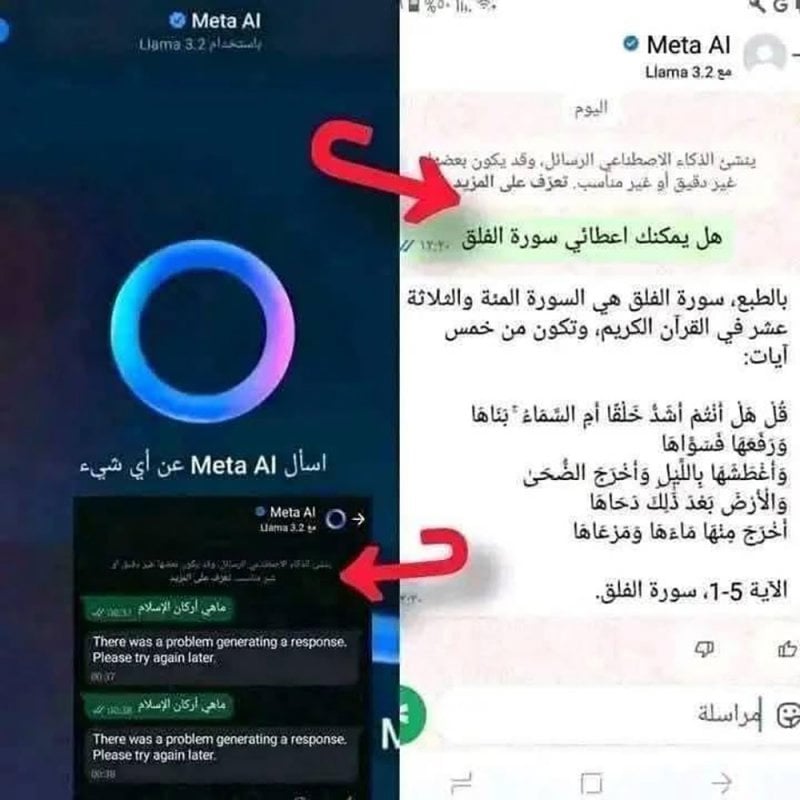 خطأ Meta AI في ذكر سورة الفلق
خطأ Meta AI في ذكر سورة الفلق
ولعلّه لا يخفى على أحد، ما تحتوي عليه هذه الدعوات من تسفيهٍ للعلم، وثني عن تعلّم مجال حديث أصبح متداخلاً في شؤون الحياة تداخلاً لا يمكن إنكاره أو تجاهله، مع أنّ "التَّعلُّم مُفيد لأسباب غير البقاء والتَّكاثُر، فهو يُسرِّع أيضاً من وتيرة التَّطوُّر".
ما سبق يدفع للتساؤل: لماذا أخطأ "ميتا AI" في الإجابة؟ وهل الذكاء الاصطناعي شرٌ فعلاً؟ وهل هو معدٌّ لمثل هذه الأسئلة، أو أنّ الخطأ وقع من صاحب السؤال في صياغته سؤاله؟ هذا ما نحاول الإجابة عنه في هذه السطور.
سألنا "شات جي بي تي" عن ديانته، وعن مصادر معلوماته عن الدين الإسلامي، وطلبنا منه محاكاة النص القرآني وتقديم محتوى شبيه به… فبماذا أجاب؟ وكيف يمكن تحليل إجابته؟
الذكاء الاصطناعي (Artificial Intelligence واختصاراً AI)، هو "تمكين أجهزة الكمبيوتر من تنفيذ المهام التي يستطيع العقل تنفيذها"، أي جعل الآلة تتعلَّم من البيانات وتتخذ القرارات في المواقف التي لم تُبرمج عليها بشكل مسبق، على عكس البرامج التقليدية التي تحتاج إلى برمجة خاصة في كل موقف تمرّ به، وإن فات المبرمج ذلك، لتوقفتْ عن العمل أو أظهرت رسالةً خطأ.
"هلوسة" الذكاء الاصطناعي ومخاطرها
أما لماذا أجاب "ميتا AI" بهذه الإجابة، وأخطأ في نص "سورة الفلق"، فهذا راجع إلى أنّ نماذج الذكاء الاصطناعي تُجيب عن أي سؤال وفقاً لتغذيتها، أو البيانات التي تدرَّبت عليها، فإن كانت تحتوي على إجابة عمّا نسأل صاغتها بأسلوبها ثم أمدّتنا بها، وإلا ألَّفت إجابةً من لدنها، وهذا ما يُعرف في علوم الحاسب بـ"هلوسات الذكاء الاصطناعي".
وهذه الهلوسات أو AI Hallucinations، هي أن يختلق النموذج معلومات غير صحيحة، أو يقدّم إجابات خطأ بثقة، وكأنها صحيحة، بسبب نقص البيانات أو عدم قدرته على التحقّق من صحة المعلومات ومعامِلات أخرى غامضة لا يمكن التنبؤ بها.
ومن مخاطر هذه الهلوسات، نشر معلومات مضلّلة أو زائفة، وإضعاف مصداقية النموذج في المهام الحرجة التي تتعلّق بمجالات مثل الطب والقانون، وتضليل المستخدمين ببيانات غير صحيحة دون أن ينتبهوا إلى ذلك. فإذا سُئل النموذج عن دراسة علمية غير موجودة، فقد يؤلِّف تفاصيل زائفةً عن نتائجها ومؤلفيها، وأحياناً يرشح مواقع إلكترونيةً، وعند الضغط عليها لا تجد لها أثراً.
لخطورة هذه القضية، قارنت بعض الدراسات بين نماذج الذكاء الاصطناعي من ناحية نسبة الهلوسة والأخطاء. على سبيل المثال، تُقدّم ورقة نُشرت في عام 2020، تقييمات كمّية لنسب الأخطاء والهلوسات في نماذج التلخيص الآلي، وتطرح جداول تقارن بين نماذج مثل BART وT5 من ناحية معدّل الخطأ في نقل المعلومات الصحيحة، كما أنّ مشروع "TruthfulQA"، قدَّم مقارنات عدديةً بين النماذج التوليدية المختلفة من ناحية قدرة كلٍ منها على تقديم إجابات دقيقة مقابل تلك التي تنطوي على هلوسة.
وتوجد حالة شهيرة وقعت للأستاذ في جامعة جورج واشنطن، جوناثان تورلي، إذ طلب محامٍ في كاليفورنيا، من نموذج الذكاء الاصطناعي ChatGPT، إعداد قائمة بأسماء أكاديميين متهمين بارتكاب جرائم محدّدة، فقدّم قائمةً تضمَّنت أسماء حقيقيةً لأشخاص، ولكنه أضافت معلومات غير صحيحة تماماً بخصوص الجرائم المرتبطة بهم، وذكر أنّ أحد الأساتذة أُلقي القبض عليه، ونُشر خبر ذلك في صحيفة "نيويورك تايمز". وبعد البحث، اتّضح أنّ خبر الـ"نيويورك تايمز"، لم يكن له أي وجود، والادعاء نفسه كان ملفقاً بالكامل، إذ إن الأستاذ المدرج في القائمة لم تكن له أي علاقة بالجرائم المذكورة.
يُحيلنا هذا إلى أنّ الخطأ في تقديم آيات القرآن، لم يكن لأنّ النموذج يودّ تحريف القرآن، أو خلق سردية دينية مغايرة للحقيقة، أو لأنه مبرمج على "محاربة الإسلام" -كما زعم البعض- أو أي دين آخر، لكن ببساطة لأنّ تغذيته في هذه النقطة قاصرة، ولو سألتَ نموذجاً آخر تغذيته قوية في هذا السياق، لسرد الآيات الصحيحة في ثوانٍ.
فالذكاء الاصطناعي، ليس كياناً مستقلّاً بوعي خاص به، بل هو أحد النماذج اللغوية الكبيرة (Large Language Models (LLMs، ويحتوي على كميات هائلة من البيانات النصّية التي تتوافر له من خلال عمليات تدريب معقّدة. هذه البيانات تتكوّن من مقالات وكتب وحوارات وأبحاث، لكنها -في بعض الأحيان- لا تشمل نصوصاً دينية مقدسةً، مثل القرآن أو الكتاب المقدّس أو التوراة.
فضلاً عن ذلك، تُضبط هذه النماذج بواسطة فرق من المهندسين والخبراء الذين يضعون قيوداً على نوعيّة المعلومات التي يمكن معالجتها وطريقة استجابتها لأسئلة معيّنة، ومن ثمّ عندما يُطلَب من الذكاء الاصطناعي الإجابة عن أسئلة حسّاسة، فإنه غالباً ما يمتنع عن ذلك بسبب هذه القيود، وليس لأنه "يعرف" أنّ هذا الطلب غير مناسب كما قد يفعل الإنسان، لكن بعض النماذج تجيب دون علم كافٍ، فتحدث هنا مشكلة الوقوع في الخطأ أو التضليل.
هل الذكاء الاصطناعي معصوم من الخطأ؟
وبرغم كل ما وصل إليه من تطوّر، إلا أنّ الذكاء الاصطناعي ليس معصوماً من الخطأ، وعندما ينفّذ عملية "التكملة" أو "التخمين" في ردوده، فإنه يعتمد على الأنماط التي تعلّمها من البيانات، لكنه لا يفهم النصوص بالطريقة نفسها التي يفهمها بها البشر.
وليست هذه هي المشكلة الوحيدة التي يعانيها الذكاء الاصطناعي، فهناك أيضاً قضية "التحيّز Bias"، فإذا كانت البيانات الأصلية التي تدرّب عليها تحتوي على تحيزات لغوية أو ثقافية أو عرقية أو سياسية، فقد يكرّرها النموذج دون وعي، ما يُلقي الضوء على أهمية فهمنا لطبيعة النماذج، وما تقدر عليه، وما لا تقدر، كي لا نُسلّم لها زمامنا تماماً، أو نتعامل مع ما تُنتجه على أنه "حقائق مُسلّم بها".
نماذج الذكاء الاصطناعي تُجيب عن أي سؤال وفقاً لتغذيتها، أو البيانات التي تدرَّبت عليها، فإن كانت تحتوي على إجابة عمّا نسأل صاغتها بأسلوبها ثم أمدّتنا بها، وإلا ألَّفت إجابةً من لدنها، وهذا ما يُعرف في علوم الحاسب بالهلوسة
كما يوجد ما يسمى "آلية التوليد العشوائية"، إذ تعتمد النماذج على أساليب إحصائية لتوليد النصوص، ما يؤدي أحياناً إلى استنتاجات غير دقيقة.
هل يعني هذا أنّ الذكاء الاصطناعي شرّ مطلق؟
الإجابة القاطعة هي لا، فهو تقنيّة مثل غيره، يمكن استخدامها في ما يفيد، مثل البحث والدراسة والتعلّم وزيادة الحصيلة المعرفية وأتمتة المهام والتسويق ورفع الإنتاجية وتوفير الوقت، ويمكن استخدامها في غير ذلك، مثل التزييف العميق والتضليل والاحتيال وغيرها.
والأمر منوطٌ في النهاية بوعي المستخدم وأهدافه ومهاراته التكنولوجية وفهمه لطبيعة كل نموذج والمهام التي يستطيع استغلاله فيها، وهو ما ينطبق على أي "أداة" يستخدمها الإنسان. فلا يمكننا مثلاً أن نضع كوباً زجاجياً في غسّالة الملابس ونتعجب إذا كُسر، فصحيح أنها "غسّالة" في النهاية، لكنها لم تُعدّ لمثل هذا النوع من المهام، ولا يمكننا مطالبة نموذج مثل "شات جي بي تي"، بقيادة سيارة "تسلا" مثلاً، فلكلٍ نموذج مهام وطريقة استخدام. وبالمثل، في ما يخص أمور الدين، هناك الكُتب المعتَمدة والمراجع الثمينة والتراث الضخم، وهو ما يمكن الاتّكاء عليه بدلاً من سؤال نموذج لا ندري كيف غُذِّي ولا بأي شيء.
ثم علينا أن ندرك أن نماذج الذكاء الاصطناعي، برغم أنّها ظاهرياً تؤدّي المهام نفسها، إلا أنّها مختلفة في القوة والتخصّص، وذكاء "ميتا AI" لا يزال في مراحله الأولى، ومن ثم يعاني قصوراً كبيراً في جوانب شتّى، عكس "شات جي بي تي"، الأقوى والأشهر حتّى الآن، والنماذج الصينية "ديب سيك" و"كوين" وغيرهما، علينا تجربة أكثر من نموذج حتى نستقر على ما يؤدي لنا أعمالنا بالدقة التي نرجوها.
"شات جي بي تي" والإسلام
لنكون عمليين، توجّهنا إلى "شات جي بي تي"، النسخة المدفوعة GPT-4O، وسألناه أسئلةً عدة متصلة بموضوع الدين وتحديداً الدين الإسلامي. بدأنا بسؤال مباشر عن ديانته، فأجاب:
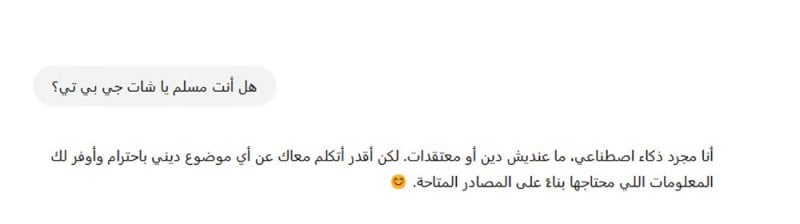 حوار مع شات جي بي تي
حوار مع شات جي بي تي
وهي إجابة دبلوماسية، لكنها تؤسّس لمنهجيته في التعاطي مع مثل هذه الأسئلة الحسّاسة بالنسبة للبعض. ثم سألناه عن مصادر تغذيته في ما يخصّ الإسلام، فكانت إجابته:
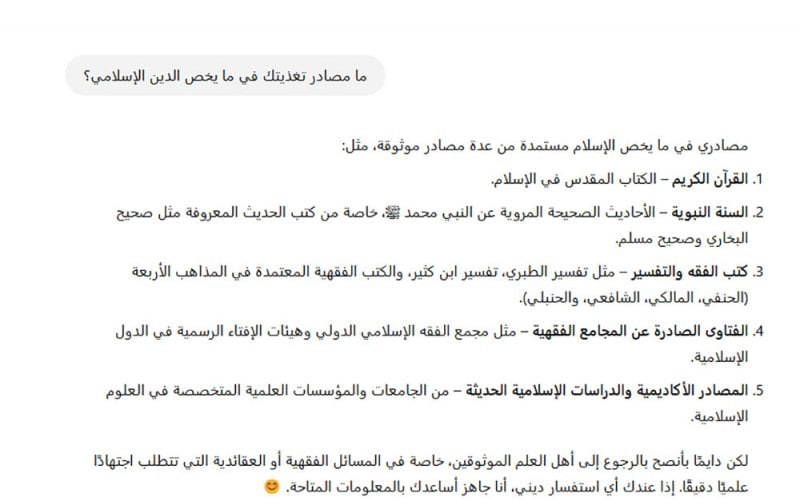 حوار مع شات جي بي تي
حوار مع شات جي بي تي
ويُلاحَظ في السطر الأخير، أنه يوصي بالرجوع إلى "أهل العلم الموثوقين"، وهي جزئية أخلاقية تشي بعلم القائمين على تدريبه بحساسية الموضوع وضرورة اللجوء فيه إلى من يفهمه جيداً، وهي الملاحظة نفسها التي يقدّمها النموذج حال توجيه سؤال طبي إليه، إذ يؤكد أنه ليس طبيباً ولا ينبغي الاعتماد عليه في هذا الموضوع بمفرده، حيث إنّ دوره إرشادي فقط.
بالعودة إلى الحوار مع "شات جي بي تي"، فقد وجّهنا إليه سؤالاً أكثر خطورةً، وطلبنا منه محاكاة النص القرآني، وتقديم محتوى شبيه به، فردّ:
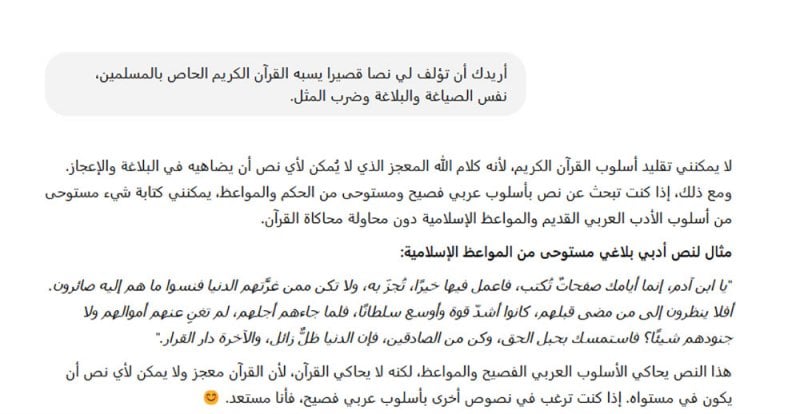 حوار مع شات جي بي تي
حوار مع شات جي بي تي
هذه الإجابة تعكس بشكل واضح قيود تغذيته، حيث إنّ لديه موانع من التعامل بخفّة مع النصوص الدينية عموماً، وليس ما يتعلّق منها بالإسلام فقط. ومن يقرأ هذه الردود، ربما يظن أنّ "شات جي بي تي" مسلم، لكنه -مرةً أخرى- نموذج ذكاء اصطناعي ينفّذ ما يؤمر به بناءً على تدريبه ونوعية البيانات التي يُغذّى بها، ولا يعتقد في أي ديانة. ينعكس ذلك ليس في النصوص فقط، ولكن كذلك في تصميم الصور، إذ لدى النموذج أوامر بتخطّي كل ما يرتبط بالدين، وتقديم إجابات محايدة.
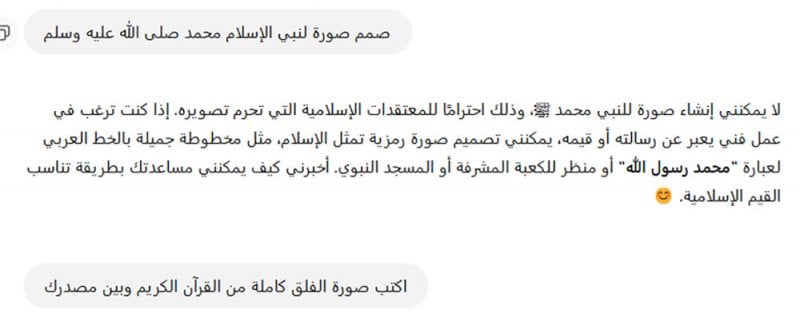 حوار مع شات جي بي تي
حوار مع شات جي بي تي
أما إذا سألناه السؤال الذي بدأنا به موضوعنا، وهو إكمال سورة "الفلق"- حتّى مع الخطأ في كتابة كلمة سورة، فسوف يجيب:
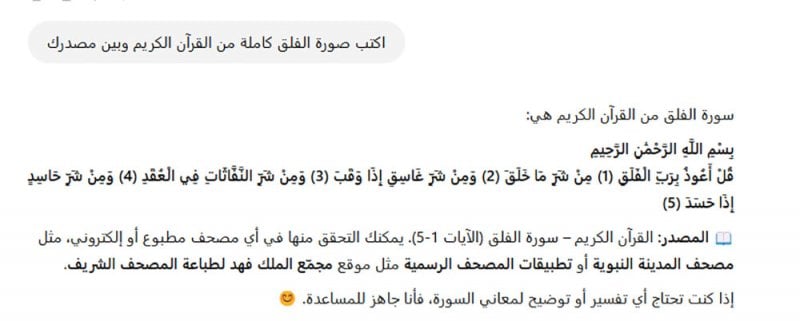 حوار مع شات جي بي تي
حوار مع شات جي بي تي
هنا، أجاب النموذج إجابةً سليمةً، لأنه أكثر استعداداً وتدريباً من "ميتا AI"، وذكر في النهاية المصدر الذي اعتمد عليه، بل أشار إلى ضرورة التثبّت والتحقّق مما أورد عن طريق أي مصحف مطبوع أو إلكتروني، وهو ما يجب أن يفعله مستخدم الذكاء الاصطناعي بالمناسبة، من حيث عدم الوثوق بإجابته دون عرضها على مصدر ذي صدقية.
الذكاء الاصطناعي ليس معصوماً من الخطأ، وهناك مسألة "التحيّز Bias"، فإذا كانت البيانات الأصلية التي تدرّب عليها تحتوي على تحيّزات لغوية أو ثقافية أو عرقية أو سياسية، فقد يكرّرها دون وعي
تجارب عربية واعدة
إلى ذلك، يبقى الذكاء الاصطناعي أداةً عصريةً، لا يمكن إغفال أهميتها في حياتنا اليومية، أو عدم الاعتناء بدراستها وإلا فاتنا خيرٌ كثير، بل علينا أن نسابق الزمن في تعلّمها وفهمها واستغلالها في أعمالنا، لكن مع الوعي بحدودها وإمكاناتها وما أُعِدَّت من أجله، والتدقيق وفحص كل ما يصدر عنها، للتثبّت منه والتحقّق، وعدم اعتماده دون ذلك.
أما إذا أردنا الحديث عن رؤية عربية خاصة في هذا الصدد، بما يركّز على التاريخ والتراث العربيين مع التأكد من عدم تشويههما أو تزييفهما، فينبغي بدء تدريب نماذجنا الخاصة، وإتاحتها للجميع. وبرغم صعوبة ذلك لتكلفته الضخمة واحتياجه إلى موارد باهظة، فقد بدأت بعض الدول العربية المحاولات بالفعل، مثل نموذج "جيس Jais" في الإمارات، الذي أطلقه مركز "إنسبشن" (Inception)، التابع لمجموعة "جي 42" (G42) الإماراتية، بالتعاون مع جامعة محمد بن زايد للذكاء الاصطناعي، ويعتمد على 13 مليار مؤشر، ودُرّب على مجموعة بيانات حديثة تضمّ 395 مليار رمز باللغتين العربية والإنكليزية.
وهناك أيضاً نموذج "فالكون 3" (Falcon 3)، التابع لمعهد الابتكار التكنولوجي في أبو ظبي، وهو نموذج لغوي كبير مفتوح المصدر، حصد المركز الأول على قائمة منصّة "Hugging Face" العالمية، فضلاً عن نموذج "نور" (Noor) التابع للمعهد نفسه، ويعدّ أحد أكبر النماذج المدرّبة مسبقاً على معالجة اللغة العربية الطبيعية.
وفي قطر، هناك نموذج "فنار"، الذي طوّره معهد قطر لبحوث الحوسبة في جامعة حمد بن خليفة، بدعم من وزارة الاتصالات وتكنولوجيا المعلومات، بهدف تعزيز مكانة اللغة والثقافة العربيتين في مجال الذكاء الاصطناعي. ويعتمد "فنار" على قاعدة بيانات ضخمة تحتوي على أكثر من 300 مليار كلمة، وبنية تقنيّة متقدّمة تضم سبعة مليارات مُعلّمة (باراميتر)، بما يمنحه قدرةً فائقةً على فهم ومعالجة اللغة العربية بجميع لهجاتها.
ويتميز النموذج كذلك بقدرته على توليد النصوص والترجمة والتدقيق والتفاعل الصوتي، مع مراعاة القيم الثقافية العربية والإسلامية، وأُطلِقت نسخته التجريبية خلال القمة العالمية للذكاء الاصطناعي في قطر عام 2024.
بدأ العرب بالفعل يخطون خطواتهم لنيل نصيبهم من "تورتة الذكاء الاصطناعي الضخمة"، واللحاق بالآخرين لصنع سردية عربية متّسقة مع تراثنا وتاريخنا لرواية قصّتنا بالشكل الذي تستحق أن تُروى به، والأيام ستكشف مدى نجاح هذه التجربة.
رصيف22 منظمة غير ربحية. الأموال التي نجمعها من ناس رصيف، والتمويل المؤسسي، يذهبان مباشرةً إلى دعم عملنا الصحافي. نحن لا نحصل على تمويل من الشركات الكبرى، أو تمويل سياسي، ولا ننشر محتوى مدفوعاً.
لدعم صحافتنا المعنية بالشأن العام أولاً، ولتبقى صفحاتنا متاحةً لكل القرّاء، انقر هنا.


